
当你向某人询问最新的复仇者电影时,他们可能不会说“ 这个服务器上的那个,在这个子域,在这个文件路径下,斜线Marvel dash Avengers dot mp4 ”。相反,他们可能会描述视频的内容:“其中一半宇宙被Thanos摧毁…… ”。这显然是一种直观的方式来考虑人类的内容,但通常不是我们今天如何访问网络上的内容。话虽如此,IPFS等分散协议实际上确实使用了这种类型的内容地址(使用文件内容标记和查找内容)在分散的网络上查找内容。
在本文中,我们将详细探讨整个过程的工作原理,涉及的不同组件以及它们如何协同工作。我们将通过向IPFS添加文件然后探索在向IPFS添加文件时发生的情况来实现此目的。(本文由IPFS中国社区编译)
它是如何工作的?
让我们首先向IPFS添加一张照片。我们将添加这个……

顺便说一句,您必须在您的系统上安装IPFS才能跟上我。你可以从这里安装它。安装IPFS后,您必须启动IPFS 守护程序(与IPFS网络通信的软件,以便从网络添加和检索数据)。你可以通过启动守护进程ipfs daemon。
将照片添加到IPFS时,会发生以下情况:

当我们在IPFS上添加照片时会发生什么
在终端我得到这个:
你可以在这里看到最后的哈希:
QmQgQUbBeMTnH1j3QWwNw9LkXjpWDJrjyGYfZpnPp8x5Lu
但是我们没有看到与2个步骤(Raw和Digest)相关的任何内容。这一切都发生在引擎盖下。
当我们添加图像时,我们将图像转换为计算机可以理解的原始数据。现在,为了使其内容可寻址(我们上面谈到的内容),我们必须提出一种方法,通过该方法我们可以将此图像数据转换为唯一标识其内容的标签。
这是哈希函数发挥作用的地方。
散列函数将数据(来自文本、照片、整本圣经等的任何数据)输入,并为我们提供输出(摘要),并给出一个输出,其输出方面是唯一的。如果我们改变该图像中的像素,那么输出将是不同的。这显示了它的防篡改属性,从而使IPFS成为自我认证文件系统。因此,如果您将此图像传输给任何人,他/她可以检查收到的照片是否已被篡改。
此外,你无法分辨输入是什么(在这种情况下,猫照片),但只是看到它的输出(摘要)。因此,这也确保了大量的安全性。
我们将Raw图像数据传递给SHA256哈希函数并获得唯一的摘要。现在,我们需要将此摘要转换为CID(内容标识符)。当我们尝试取回图像时,此CID是IPFS将搜索的内容。为此,IPFS使用名为Multihash的东西。
要了解Multihash的重要性,请考虑这种情况。
您将此图像存储在互联网上,并且您拥有其CID,您可以将其提供给任何想要获取此图像的人。现在,如果您将来发现SHA256被破坏(这意味着此过程不再具有防篡改和安全性)并且您想要使用SHA3(以确保防篡改和安全性),那该怎么办呢?这意味着要改变将照片转换为CID的整个过程,之前的CID将毫无用处……
在这种情况下,上述问题似乎可能是一个小问题,但您应该知道这些哈希函数可以获得数十亿美元的资金。所有银行,国家安全机构等都使用这些散列函数来安全地运行。如果没有它,即使是浏览器上每个站点地址旁边看到的绿色锁也无法运行。
为了解决这个问题,IPFS使用Multihash(多哈希)。Multihash允许我们定义自定义的散列。因此,根据使用的哈希函数,我们可以有多个版本的CID。我们将在本系列的第4部分中详细讨论Multihashes,它将深入研究Multiformat(多格式)。
现在我们已将我们的照片添加到IPFS,但这不是全部故事。实际发生的事情是这样的:
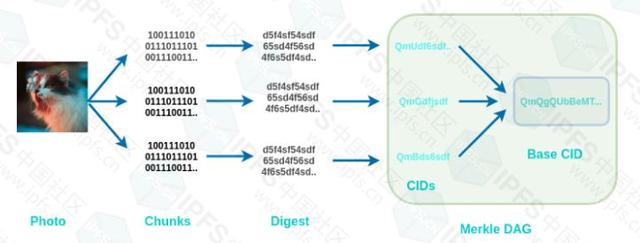
大文件被分块,散列并组织成IPLD(Merkle DAG对象)
如果文件大于256 kB,则它们被分解为更小的部分,因此所有部分都等于或小于256 kb。我们可以使用此命令查看照片的块:
ipfs object get Qmd286K6pohQcTKYqnS1YhWrCiS4gz7Xi34sdwMe9USZ7u
这给了我们15个块,每个块小于256kb。首先将这些块中的每一个转换为摘要,然后转换为CID。
IPFS使用IPLD(IPLD使用Merkle DAG或有向非循环图)来管理所有块并将其链接到基本CID。
IPLD(对象)由2个组成部分组成:
Data – 大小<256 kB的非结构化二进制数据blob。
Links – 链接结构数组。这些是指向其他IPFS对象的链接。
每个IPLD链接(在我们的例子中是我们上面提到的15个链接)有3个部分:
Name – 链接的名称
Hash – 链接的IPFS对象的哈希值
Size – 链接的IPFS对象的累积大小,包括其链接
IPLD建立在关联数据的思想基础之上,这实际上是分散的网络社区中的人们已经谈论了很长一段时间。这是Tim Berners-Lee多年来一直在努力的事情,他的新公司Solid正在围绕它开展业务。
使用IPLD还有其他好处。为了看到这个,让我们创建一个名为photos的文件夹,并在其中添加2张照片(猫图片和相同图片的副本)。

正如您所看到的,这两张照片都具有相同的哈希值(这证明我没有更改图像副本中的任何内容)。这为IPFS 添加了重复数据删除属性。因此,即使您的朋友将相同的猫照片添加到IPFS,他也不会复制图像。这节省了大量的存储空间。
想象一下,如果我将这篇文章存储在IPFS上,并且它的每个字母都是分块的并且具有唯一的CID,那么这整篇文章可以通过字母表(大写和小写),数字和一些特殊字符的组合来构建。我们只会存储每个字母、数字和字符ONCE,并根据数据结构中的链接重新排列它。这是强大的东西……
IPFS还有一个名为IPNS的命名系统。要了解它的重要性,让我们假设您创建了一个网站,并将其托管在某个域上。对于此示例,我们将访问我的网站:https://vaibhavsaini.com
如果我想在IPFS上托管它,我只需在IPFS上添加网站文件夹。为此,我已经使用了下载网站wget。如果您使用的是基于Linux的操作系统,如Ubuntu或MAC,那么您可以和我一起试用。
下载网站(或任何网站):
wget –mirror –convert-links –adjust-extension –page-requisites –no-parent https://vaibhavsaini.com
现在添加名为vaibhavsaini.com IPFS 的文件夹:
ipfs add -r vaibhavsaini.com
你会得到这样的东西:
我们可以看到,我们的网站现在托管在最后一个CID(该文件夹的CID)上:
QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
我们可以使用http协议访问该站点:
https://gateway.pinata.cloud/ipfs/QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB/
假设我想在网站上更改我的个人资料图片。正如我们上面已经了解到的,如果我们改变输入的内容,我们会得到一个不同的摘要,这意味着我的最终“基本CID”会有所不同。
这意味着每次更新我的网站时都必须更新哈希。每个拥有我之前网站链接的人(上述网址)都无法看到我的新网站。
这可能会导致很大的问题。
为解决此问题,IPFS使用星际命名系统(IPNS)。使用IPNS链接指向CID。如果我想更新我的网站CID,我只需要将新的CID指向相应的IPNS链接(这类似于今天的DNS)。我们将在本系列的第3部分中深入探讨IPNS。
但是现在,让我们为我的网站生成一个IPNS链接。
ipfs名称发布
QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
这可能需要几分钟时间。你会得到这样的输出:
发布到Qmb1VVr5xjpXHCTcVm3KF3i88GLFXSetjcxL7PQJRviXSy:/ ipfs / QmYVd8qstdXtTd1quwv4nJen6XprykxQRLo67Jy7WyiLMB
现在,如果我想添加更新的CID,我将使用相同的命令
ipfs name publish <my_new_CID>
使用此功能,您可以使用以下链接访问我的网站的更新版本:
https://gateway.pinata.cloud/ipns/Qmb1VVr5xjpXHCTcVm3KF3i88GLFXSetjcxL7PQJRviXSy
上述链接仍然不是人类可读的。我们习惯于这样的名字:https://vaibhavsaini.com。在本系列的第3部分中,我们将看到如何将IPNS链接链接到域名,以便您可以在https://vaibhavsaini.com上查看我的IPFS托管网站。
IPFS也是HTTP协议的潜在替代品。但为什么我们要替换HTTP呢?它看起来效果不错,对吧?我的意思是你能够阅读这篇文章并在Netflix上看电影,所有这些都使用HTTP协议。
即使它似乎对我们很好,它也有一些大问题。
假设您正坐在演讲厅,您的教授会要求您访问特定网站。讲座中的每个学生都向该网站提出请求并得到回复。这意味着相同的确切数据被单独发送给房间中的每个学生。如果有100名学生,则有100个请求和100个回复。这显然不是最有效的做事方式。理想情况下,学生将能够利用他们的物理接近度来更有效地检索他们所需的信息。
如果网络通信线路中存在某些问题并且客户端无法与服务器连接,则HTTP也会出现大问题。如果ISP发生中断,某个国家/地区阻止某些内容,或者内容只是被删除或移动,就会发生这种情况。这些类型的断开链接存在于HTTP Web上的任何位置。
HTTP的基于位置的寻址模型鼓励集中化。使用我们的所有数据信任少数几个应用程序是很方便的,但由于这一点,网络上的大部分数据都变得不真实。这使得这些提供商对我们的信息负有巨大的责任和权力。
这是Libp2p的用武之地。Libp2p用于在IPFS网络上传输数据并发现其他对等设备(计算机和智能手机)。这种方式的工作方式是,如果每台计算机和智能手机都运行IPFS软件,那么我们将成为像网络这样的大型BitTorrent的一部分,每个系统都可以充当客户端和服务器。因此,如果100名学生请求相同的网站,他们可以互相请求网站数据。如果大规模实施这种系统,可以显着提高上网速度。
好的,我们就此止步。如果你已经到了这里,那么你应该拍拍你的背。做得好。
到目前为止,我们已经学到了很多关于IPFS的知识。让我们回顾一下:
IPFS是内容可寻址的。IPFS上的数据使用CID进行识别。
这些CID对于它引用的数据是唯一的。
IPFS使用散列函数来实现防篡改属性,这使得IPFS成为自我认证文件系统。
IPFS使用Multihash,它允许它为相同的数据提供不同版本的CID(这并不意味着CID不是唯一的。如果我们使用相同的哈希函数,那么我们将拥有相同的CID。我们将更多地讨论这个问题。在本系列的第4部分中)。
IPFS使用IPLD来管理和链接所有数据块。
IPLD使用Merkle DAG(又称有向无环图)数据结构来链接数据块。
IPLD还为IPFS 添加了重复数据删除属性。
IPFS使用IPNS将CID链接到固定IPNS链路,这类似于当前集中式互联网的DNS。
IPFS使用Libp2p在IPFS网络上传输数据并发现其他对等方(计算机和智能手机),这可以显着提高网上冲浪的速度。
下面是IPFS堆栈的图解表示。
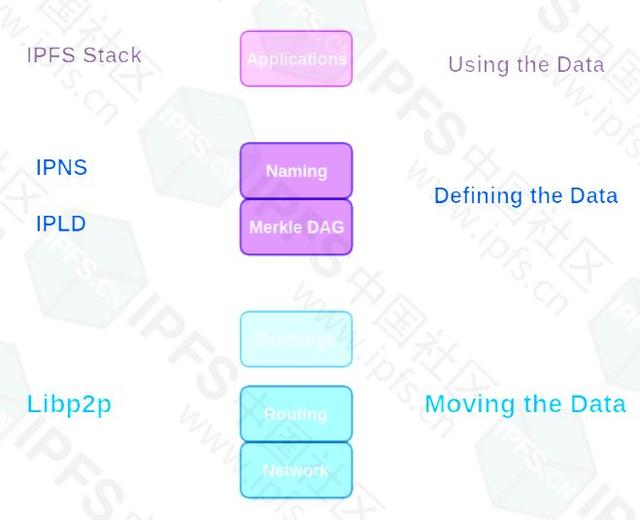
IPFS堆栈
作者:Vaibhav Saini
本文由IPFS中国社区编译





